Redis 기반의 분산 락, 그리고 Redlock 알고리즘
Redis 기반의 분산 락, 그리고 Redlock 알고리즘
분산 락(Distributed Lock)은 여러 프로세스나 노드가 공유 리소스에 동시에 접근할 수 있는 분산 환경에서 리소스를 안전하게 제어하기 위해 사용하는 락 매커니즘이다.
오늘 주제는 아래와 같은 답에 대한 대답을 찾기 위한 것이다.
- 공연장 티켓 예매를 할 때 어떻게 같은 좌석이 동시에 여러 사람에게 판매되는 것을 막을 수 있을까?
- 여러 노드에서 cron job을 실행할 때 한 번만 실행하게 할 수 있는 방법은?
- 결제 관련 DB와 상품 재고 관련 DB가 분리되어 있을 때, 어떻게 transaction 처리를 할 수 있을까?
분산 시스템에서 발생할 수 있는 문제들
경쟁 조건(Race Condition) 발생
- 여러 노드가 동시에 같은 자원에 접근해 작업하면서 작업 순서가 꼬이는 경우
- 두 서버가 동시에 DB에서 같은 값을 읽고 수정할 경우 나중에 수정한 값만 남는 경우 등
중복 작업 발생
- 동일한 작업이 여러 노드에서 중복 실행되는 경우
- 여러 노드에서 병렬로 수행되는 cron 작업
데이터 일관성 붕괴
- 분산 시스템의 각 노드가 서로 다른 시점의 데이터를 READ 하면서 데이터 일관성이 깨짐
- 결제 시스템에 A, B 서버가 결제를 담당한다고 가정
- 상품의 재고가 1개만 남은 상황
- A 서버가 재고가 1개 남은 것을 확인함과 동시에 B 서버에서 결제를 진행하며 재고를 1 감소시키면, A 서버에서 결제를 진행하는 과정에서는 사실 재고가 0인 문제 발생
리더 선출 이슈
- 여러 노드 중에 딱 1개의 노드만 리더로 선출되어야 함. 동시에 여러 노드가 리더로 선출되어서는 안됨.
- 카프카에서 브로커 간 조율을 위해 리더 브로커를 선출하는 경우
Lock의 목적
Efficiency
동일한 작업을 여러 노드가 반복함으로써 불필요한 비용이 발생하는 것을 방지하기 위해 Lock을 사용할 수 있다.
Correctness
Concurrent한 프로세스들이 동일한 자원에 접근하고 수정하려 하여 발생하는 일관성 훼손, 오염된 데이터 등을 방지하기 위해 Lock을 사용할 수 있다.
Martin Kleppmann(Designing Data-intensive Applications 저자)에 따르면 분산 락을 도입할 때는 Efficiency와 Correctness 중 어떤 문제를 해결하기 위해서 도입하는지 명확히 이해해야 한다고 한다.
예를 들어, Efficiency를 위한 분산 락 도입이라면 Redlock Algorithm은 적합하지 않을 수 있다. 동일한 작업의 반복을 줄이기 위해 서로 다른 5대의 Redis master를 두고 다수의 master에서 lock 획득을 시도하는 비용이 더 클 가능성이 높기 때문이다.
Redis를 이용한 분산 락 구현
Redis는 싱글 스레드 기반의 인 메모리 저장소로 읽기와 쓰기가 빠르고, 싱글 스레드에서 한 번에 하나의 커맨드씩 순차 처리되기 때문에 락 구현에 자주 이용된다.
분산 환경에서 동작하는 cron 작업 예시
이중화된 여러 노드가 존재하는 환경에서 cron 작업은 회당 1번만 동작하도록 하는 예시를 구현해 본다.
- 여러 개의 노드에서 cron 작업이 실행될 수 있다
- 하나의 노드에서 먼저 cron 작업이 시작되면, 다른 노드에서는 해당 작업을 실행하지 않아야 한다
cron으로 수행되는 작업 정의
10초 간 작업이 수행되는 것을 mockgin했다.
func runCronTask() {
// 실제 실행할 크론 작업 (여기선 10초 대기)
fmt.Println("작업 중... ⏳")
time.Sleep(10 * time.Second)
fmt.Println("작업 완료! 🎉")
}
메인 구조
lock이 걸려 있으면 실행하지 않으며, lock이 걸려 있지 않으면 작업을 실행한다.
func main() {
ctx := context.Background()
// Redis 클라이언트 생성
client := newRedisClient("localhost:6379", "", 0)
// 분산 락 획득 시도
acquired, err := client.acquireLock(ctx, lockKey, lockTTL)
if err != nil {
log.Fatalf("Redis 연결 오류: %v", err)
}
if !acquired {
fmt.Println("다른 서버에서 이미 크론 작업 실행 중! 🚫")
return
}
fmt.Println("크론 작업 실행 시작... ✅")
// 크론 작업 실행 (예: 데이터 백업)
runCronTask()
// 락 해제
client.releaseLock(ctx, lockKey)
fmt.Println("크론 작업 완료, 락 해제 🔓")
}
newRedisClient는 acquireLock과 releaseLock 메서드를 가지는 redis client를 생성하는 생성자다. 아래에서 구현 코드는 다시 설명한다.
Lock 구현
import "github.com/redis/go-redis/v9"
// 락 관련 상수
const lockKey = "cron:job:my-task"
const lockTTL = 30 * time.Second // 락 유지 시간
// 분산 락에 사용할 redis client
type redisClient struct {
client *redis.Client
}
func newRedisClient(addr, password string, db int) *redisClient {
return &redisClient{
client: redis.NewClient(&redis.Options{
Addr: addr, // Redis 주소
Password: password, // 패스워드 (없으면 빈 문자열)
DB: db, // 기본 DB
}),
}
}
// acquireLock 락 획득 메서드
func (r *redisClient) acquireLock(ctx context.Context, key string, ttl time.Duration) (bool, error) {
ok, err := r.client.SetNX(ctx, key, "locked", ttl).Result()
if err != nil {
return false, err
}
return ok, nil
}
// releaseLock 락 해제 메서드
func (r *redisClient) releaseLock(ctx context.Context, key string) {
r.client.Del(ctx, key)
}
락의 획득과 해제는 go-redis의 SetNX를 이용했다.
참고로 SetNX 명령어는 deprecated된 명령어지만 go-redis에서는 SetNX를 지원하고 있으며 내부적으로는 Set 명령어를 이용해 not exist 상황에서 set을 하고 있다.
Lock 설정을 할 때는 TTL을 두어 데드락을 방지한다.
주의사항 및 고려점
- 데드락 방지: TTL(타임아웃)을 설정해 락이 무한정 걸려 있지 않도록 관리.
- 락 재확인: 락이 만료되었을 수 있으니, 작업 중간에 락 상태를 재확인하는 로직 추가.
- 락 이중 확인: Redlock 같은 알고리즘을 사용해 분산 환경에서 락의 안정성을 강화.
지금까지는 Redis가 싱글 인스턴스인 상황을 고려해서 Lock 구현을 했다. 하지만, 이 구현에는 한 가지 큰 문제가 존재한다.
Redis가 SPoF(Single Point of Failure)가 된다는 점이다.
그렇다면 싱글 인스턴스가 아니라 master-slave 구조면 되는 것 아닌가? 답은 그렇게 간단하지 않다.
RedLock 알고리즘
Master Slave 구조의 헛점
- Client A가 master로부터 lock을 획득
- master가 replica에 lock 정보를 전달하기 전에 crash 발생으로 down
- replica는 master로 승격됨
- Client B는 replica였던 master로부터 lock을 획득. 그러나 이 리소스는 A가 아직 작업하고 있는 리소스임.
RedLock 알고리즘
Redlock 알고리즘은 여러 개의 Redis 노드에서 락을 획득하여, 하나의 Redis 인스턴스가 장애를 겪더라도 전체 시스템의 일관성과 신뢰성을 유지할 수 있도록 한다.
- 여러 Redis 인스턴스 사용: Redlock은 여러 Redis 서버에 락을 요청하여, 시스템이 하나의 Redis 노드 장애에 영향을 받지 않도록 함. 이를 위해 최소 5개의 Redis 노드가 필요.
- 락을 획득하려면 과반수 이상의 Redis 서버에서 락을 획득해야 함. 예를 들어, 5개의 Redis 서버가 있을 때 3개 이상의 서버에서 락을 획득해야 해당 락을 유효하다고 판단.
- 락의 유효성 검증: 각 Redis 서버에서 락을 획득하는데 소요되는 시간이 달라질 수 있으므로, 락을 획득한 후의 만료 시간을 검증하여 락이 유효한지 확인.
Redlock 알고리즘 동작 과정
클라이언트는 다음과 같은 순서로 동작한다.
- 현재 시간을 밀리초로 기록
- 동일한 키와 랜덤 값으로 모든 N개의 Redis 인스턴스에서 순차적으로 락을 시도. 각 시도에는 짧은 타임아웃을 설정해, 노드가 다운되면 바로 다음 인스턴스 이동.
- 락을 획득하는 데 걸린 시간을 계산하고, N개의 인스턴스 중 과반수 이상에서 락을 획득하고, 걸린 시간이 락의 유효 시간보다 짧으면 락을 획득했다고 판단.
- 락을 획득하면, 유효 시간은 초기 유효 시간에서 걸린 시간을 뺀 값으로 설정.
- 락을 획득하지 못한 경우, 혹은 락의 유효시간이 마이너스인 경우(획득 과정에서 초과됨), 모든 인스턴스에서 락을 해제.
장점
- 높은 가용성: 여러 Redis 서버를 사용하기 때문에 하나의 서버가 다운되더라도 락이 계속해서 유지.
- 높은 신뢰성: 여러 서버에서 락을 획득해야 하기 때문에 분산 시스템에서의 신뢰성을 보장.
- 고급 분산 락: Redlock은 분산 시스템에서 안전한 락을 제공하며, 상호 배타적인 작업을 보장.
단점
- 복잡성: 여러 Redis 서버와 통신해야 하므로 구현이 다소 복잡.
- 성능 저하: 각 서버와 통신하는 데 시간이 소요되므로 성능 저하. 락 획득에 실패할 경우 재시도 로직을 구현해야 하므로, 대규모 분산 환경에서는 성능에 영향.
- Redis 노드 간의 시간 동기화 필요: Redlock은 여러 서버에서 락을 획득하고 만료 시간을 계산하므로, 각 서버의 시간이 정확히 동기화되어야 함.
고려사항
- 각 Redis master는 독립된 컴퓨터나 VM에서 실행되어 서로 독립적으로 실행 중이어야 한다.
- split brain condition을 최소화 하기 위해서 이론적으로는 client는 multiplexing을 이용해서 N개의 master에 동시에 SET command를 전송해 다수의 master에서 최대한 빠르게, 동시에 lock을 획득해야 한다.
- 다수의 master에서 lock 획득에 실패한 클라이언트는 key 만료를 기다리지 말고 즉시 획득한 lock을 release해야 한다.
한계
아래 내용은 Martin Kleppmann의 블로그에 정리된 Redlock 알고리즘의 한계를 정리한 것이다. https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
분산 락 자체는 아래와 같은 잠재적 crash 요소를 가지고 있다.
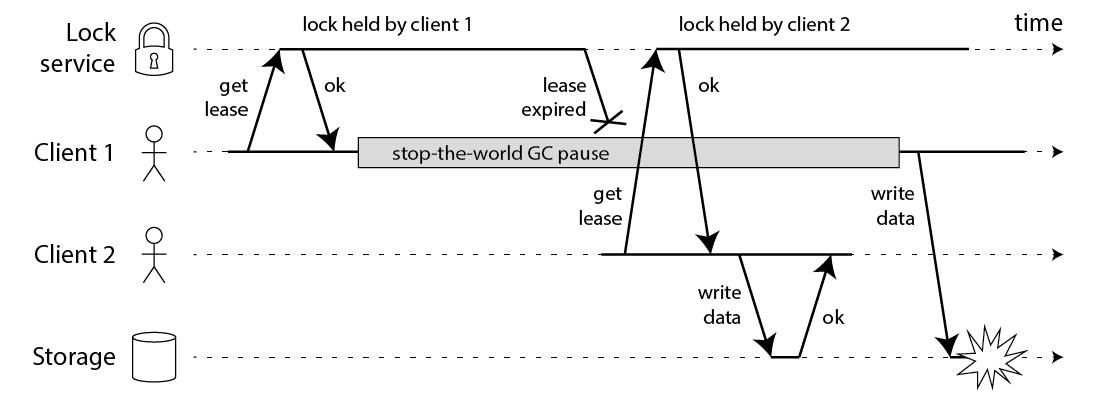
Martin Kleppmann, How to do distributed locking
- client 1이 lock 획득에 성공하고 storage write를 시도하는 도중 지연이 발생 (GC, 네트워크 지연 등)
- 그 사이 lock이 expire됨
- client2가 lock을 획득하고 client1의 작업이 종료되기 전에 storage에 write를 완료
- client1이 storage에 write를 완료 (data corruption!)
이를 해결하기 위해 fencing token을 사용할 수 있다. fencing token은 점진적으로 증가하는 숫자로 된 토큰인데, 만약 storage에 write요청이 들어왔을 때 해당 fencing token의 숫자가 직전에 write에 성공한 fencing token의 숫자보다 더 낮다면 old token으로 간주해 write 작업을 거부하는 것이다.
문제는 Redlock Algorithm이나 Redis가 내부적으로 이런 매커니즘을 제공하지 않는다는 점이며, 설사 억지로 제공하더라도 서로 다른 n개의 마스터가 완전히 동기화된 fencing token을 제공할 수 있어야 한다는 문제가 발생한다.
Timing 관련 이슈
각 노드가 생각하는 시간은 정확히 동기화되지 않으며, 여러 이유에서 몇 분까지도 차이가 날 수 있다.
이런 이유에서 분산 환경에서 타이밍 이슈는 문제가 될 수 있는데, 특히 Redlock 알고리즘은 timing에 크게 의존하고 있기 때문에 잠재적으로 문제가 발생할 수 있다.
However, Redlock is not like this. Its safety depends on a lot of timing assumptions: it assumes that all Redis nodes hold keys for approximately the right length of time before expiring; that the network delay is small compared to the expiry duration; and that process pauses are much shorter than the expiry duration.
이런 이유로 인해 Martin Kleppmann은 Redlock Algorithm이 간단하지도 않고 정확함을 보장하지도 않기에 분산 시스템의 Locking 매커니즘으로는 적합하지 않다고 주장한다.
Go로 Redlock 쉽게 쓰기
Redsync 라이브러리를 이용하면 쉽게 Redlock Algorithm을 적용할 수 있다.
func main() {
// redis connection pool을 생성
redisAddrs := []string{
"localhost:6379",
"localhost:16379",
"localhost:26379",
"localhost:36379",
"localhost:46379",
}
var pools []redsyncredis.Pool
for _, addr := range redisAddrs {
client := redis.NewClient(&redis.Options{
Addr: addr,
})
pools = append(pools, goredis.NewPool(client))
}
// redis connection pool을 이용하여 redsync 인스턴스를 생성
rs := redsync.New(pools...)
mutexname := "my-global-mutex"
// 주어진 mutexname을 이용하여 Mutex 인스턴스를 생성
mutex := rs.NewMutex(mutexname)
// Lock을 획득하여 다른 프로세스나 스레드가 Lock을 획득할 수 없도록 함
if err := mutex.Lock(); err != nil {
panic(err)
}
// 작업 수행
{
// do something
time.Sleep(1 * time.Second)
}
// Lock을 해제하여 다른 프로세스나 스레드가 Lock을 획득할 수 있도록 함
if ok, err := mutex.Unlock(); !ok || err != nil {
panic("unlock failed")
}
}
마치 평범하게 Lock을 사용하듯 NewMutex로 생성한 mutex 인스턴스에서 Lock, Unlock 메서드를 호출해 Lock을 획득하거나 풀 수 있다.
Redsync는 어떻게 Redlock 알고리즘을 구현할까?
먼저 Mutex 구조체를 보면 아래와 같다.
type Mutex struct {
name string
expiry time.Duration
tries int
delayFunc DelayFunc
quorum int
pools []redis.Pool
// ...
}
내부적으로 lockContext 메서드가 실행되는데 아래와 같은 시그니처를 가지고 있다.
func (m *Mutex) lockContext(ctx context.Context, tries int) error
tries 횟수 이내에서 락 획득을 시도하며, 실패하면 재시도한다. 재시도 딜레이는 Redlock 알고리즘 원칙에 따라서 random하게 진행한다.
func(tries int) time.Duration {
return time.Duration(rand.Intn(maxRetryDelayMilliSec-minRetryDelayMilliSec)+minRetryDelayMilliSec) * time.Millisecond
},
다시 lockContext 메서드로 돌아가 보면,
n, err := func() (int, error) {
// ...
return m.actOnPoolsAsync(func(pool redis.Pool) (bool, error) {
return m.acquire(ctx, pool, value)
})
}()
m.actOnPoolsAsync라는 함수를 실행한다. 이 함수는 함수를 받아서 pool을 순회하며 실행한다. 그리고 락에 획득한 마스터 수와 에러를 반환한다.
func (m *Mutex) actOnPoolsAsync(actFn func(redis.Pool) (bool, error)) (int, error) {
// ...
for node, pool := range m.pools {
go func(node int, pool redis.Pool) {
r := result{node: node}
r.statusOK, r.err = actFn(pool)
ch <- r
}(node, pool)
}
// ...
// lock 획득에 성공한 수를 count하여 n에 저장
for range m.pools {
r := <-ch
if r.statusOK {
n++
// ...
// n 반환
return n, err
}
그리고 lockContext 함수에서는 이 결과를 n, err로 받고 있다.
마지막으로 lockContext 함수는 아래처럼 quorum 이상의 lock 획득에 성공했는지, 아직 락 유효시간이 남았는지 검증한다.
if n >= m.quorum && now.Before(until) {
m.value = value
m.until = until
return nil
}